Project / research tooling
scholar-kit
On this page

Research workflow / AI Skill
不让 AI 编文献,而是让它去真实数据库查。
把中文人文社科检索、下载、引用、综述辅助组织成可被 Agent 调用的科研工作流。
7检索源
MIT开源协议
16★GitHub
Overview
scholar-kit 是一个面向科研场景、尤其偏向人文社科的 AI Skill。它支持知网、OpenAlex、Semantic Scholar、arXiv、NSSD、DBLP、BASE 七个检索源,一句话安装,用自然语言驱动“检索 → 下载 → 阅读 → 引用 → 综述”的工作流。
它把“找文献、整理元数据、生成引用、辅助综述”这些原本分散的动作,组织成一条可以重复调用的流程,目标是减少检索和格式整理里的机械重复,而不是替代研究判断。
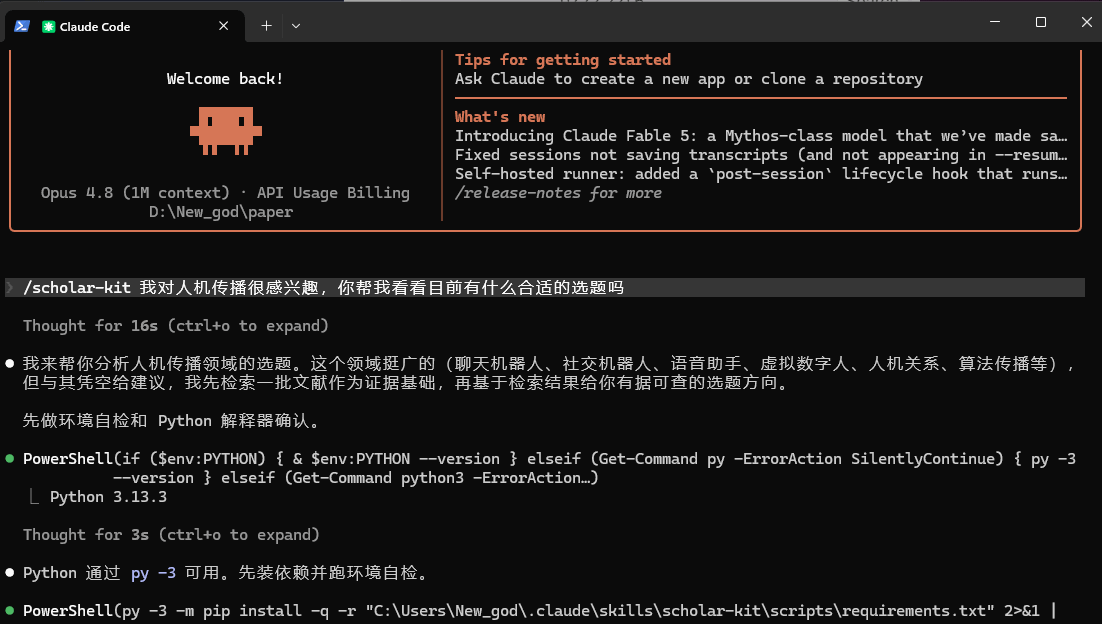
Preview

Why
做这个项目,一开始是被几个具体的痛点逼出来的:
- AI 爱编造文献。直接让大模型“给我几篇相关论文”,它经常返回看起来很像、实际不存在的标题、作者和 DOI。与其让模型凭记忆生成,不如让它去真实数据库检索、拿回可核对的题录。
- 现有学术 Skill 偏理工科。GitHub 上同类工具大多围绕 arXiv、Semantic Scholar 这类英文、理工科数据源,对中文人文社科很不友好。我更聚焦人文社科,所以把知网、CSSCI / 北大核心、NSSD 这些放在了第一位。
- 资料组织比写作更耗时。同一个关键词要在多个源之间反复搜;找到论文还要逐条整理标题、作者、年份、卷期页码、DOI、来源。
- 引用格式反复返工。GB/T 7714、APA、MLA、Chicago 之间来回切换,手动维护极易出错。
- 综述被“收集资料”拖慢。真正的判断和写作,常常卡在前面那段机械劳动上。
> 不让 AI 凭空“记得”文献,而是让它去查得到、对得上、引得准。面向人文社科,而不是又一个 arXiv 包装层。
What it does
- 多源检索:知网、OpenAlex、Semantic Scholar、arXiv、NSSD、DBLP、BASE 七个源;知网侧支持核心期刊(北大核心 / CSSCI / CSCD)、文献类型、字段与高级搜索,支持多源并发。
- 下载与全文:知网 PDF / CAJ 批量下载、断点续传、风控冷却;期刊 HTML 与硕博 PDF 全文抓取并本地缓存。
- 引用与导出:GB/T 7714、APA、MLA、Chicago、BibTeX、RIS、脚注;可导出 BibTeX / RIS / Markdown / JSON / Excel,并导入 NoteExpress / Refworks 题录。
- 引文网络与趋势:基于 Semantic Scholar 的前向 / 后向引用追踪;对搜索结果做年份、高频关键词、高被引、来源分布的聚合分析。
- Agent 工作流:文献综述、引用建议、对比矩阵、阅读笔记、学术表达优化等由 Agent 结合脚本完成。
Install & use
它被设计成“一句话安装”:在支持 fetch 的 AI Agent(Cursor / Claude Code / Gemini CLI 等)里发一条指令,Agent 会自动识别平台、clone 到正确位置、装好依赖并验证环境。
Fetch and follow instructions from https://raw.githubusercontent.com/lottshin/scholar-kit/main/setup.md
装好之后不需要记命令,直接用自然语言下指令即可:
"帮我搜关于乡村振兴的核心期刊论文" "搜 20 篇新闻传播的 CSSCI 论文并下载" "读取我的论文,帮我写一段文献综述" "这篇论文被哪些后续研究引用了?" "分析一下这批搜索结果的研究趋势"
Agent 会识别意图、调用对应脚本,完成检索、下载、引用与写作辅助。环境要求 Python 3.9+;知网相关功能需要 Edge / Chrome 与校园网或机构认证,纯 API 源则任何网络环境都能用。
My role
- 独立设计并实现整个 Skill:检索源适配、下载与全文管线、引用与导出。
- 设计“一句话安装 + 自然语言驱动”的使用方式,适配 Cursor / Claude Code / Gemini CLI。
- 规划 Agent 工作流,把综述、引用建议等高层任务落到脚本能力上。
- 维护文档与后续迭代,目前 MIT 开源、16 star。
Notes
这个项目比较像我个人兴趣的交叉点:新闻传播、学术写作、AI 工具链和开源实践。
它对我来说不是单纯的“论文搜索器”,而是一个观察学术工作流如何被工具与 Agent 重新组织的实验。